
By Samhir Vasdev
Quality, fact-based news—and trust between citizens and journalists—is essential to helping people make informed decisions about important issues. But traditional methods to evaluate media content are resource-intensive and time-consuming. Pilot research by IREX suggests that, while computers will likely not replace human insight entirely, they can make the process of evaluating impartiality of media content more efficient, scalable, and consistent.
Download the full report here – Can machine learning help us measure the trustworthiness of news?
The problem
For years, IREX has used its Media Content Analysis Tool (MCAT) to measure the quality of journalism. The MCAT provides a framework for trained media professionals to read news articles and score them according to 18 indicators of media quality—indicators like whether the author cites credible sources or fairly presents different sides of a story. The MCAT helps teams like IREX’s USAID-funded Mozambique Media Strengthening Program (MSP) measure whether its trainings with journalists are improving the quality of their reporting.
But the MCAT is a time-consuming process. Evaluators can devote almost four hours every day scoring news articles, spending between 10 and 25 minutes on each one. The process can also be inconsistent. In an audit, we discovered that one of the 18 indicators was scored differently than their original values in 4 of 7 articles.
As a result, the MSP team is spending more time finding the journalists who need more support, and less time providing that assistance to them. And digital technologies are enabling the proliferation of online media content far quicker than evaluators can track and analyze it. Can we measure media quality more efficiently?
The opportunity
Our intuition suggests that machine learning can help address this problem. As USAID highlighted in a recent report about artificial intelligence for global development, machine learning shows “tremendous potential for helping to achieve sustainable development objectives globally,” including by improving efficiencies or providing new insights that can amplify the impact of global development programs. This led us to wonder: How could machine learning technologies make evaluating media content more time-efficient, consistent, and scalable?
We’re certainly not the first to make the connection between machine learning and media quality. Initiatives like Chequeado, FakerFact, and Deep News are applying this tool in the fight against fake news. But a lack of training data—that is, examples of fake news evaluated and tagged by professionals for the software to learn from—means that even some of the best AI models are only 65% accurate. Our MCAT, with its archive of thousands of news articles already evaluated for their quality, could serve as fodder to train software to discern fact from fiction in news articles.
If we are to take full advantage of the promises of this technology, we as practitioners need more practical experience and exposure to machine learning—including understanding its limitations (such as how it entrenches our biases). As USAID reminds us, we as development practitioners have the “responsibility” to understand how these technologies are applied, and how they influence the communities we work in.
The experiment
Since working with machine learning is a new territory for a media support organization like IREX, we partnered with Lore.Ai, an artificial intelligence startup, to help us navigate the experiment. Together, we identified one of the 18 MCAT indicators to test: whether journalists insert their own opinion and bias into news stories that are supposed to be objective.
This image explains our process, which took place in mid-2018 over the course of about 2 months: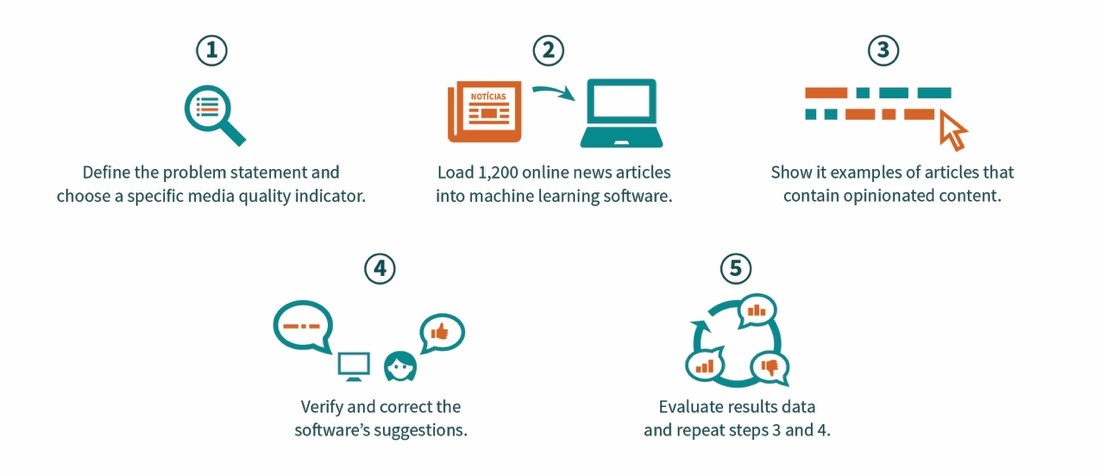
Training the evaluators to use the software was an important part of the experiment. In addition to building valuable skills working with machine learning software and interpreting its results, the local team of evaluators also gave useful user feedback to Lore, the technology partner, which were often rolled into updated versions of the software.
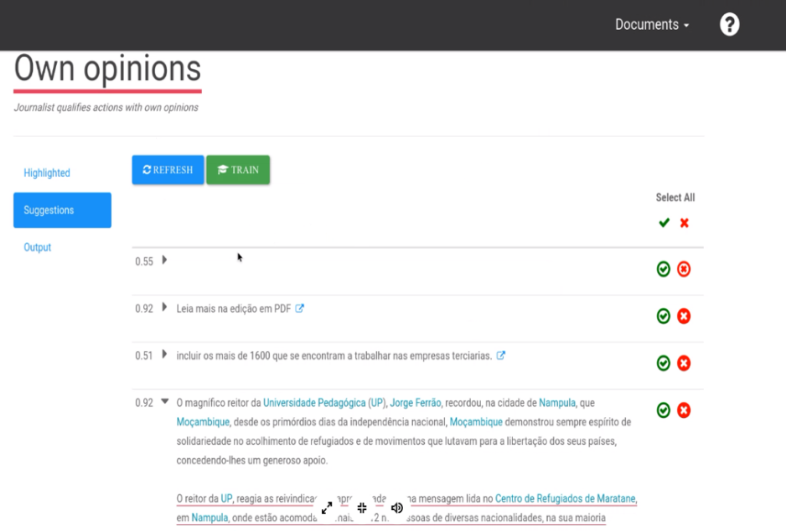
In practice, the experiment didn’t run quite as smoothly as the visual suggests, and we had to course-correct a couple times. For instance, halfway through the experiment, we realized that we had been “confusing” the machine learning software. Although it was getting better at identifying opinions in articles, our evaluators noticed that these opinions belonged to someone else (like a quote from a political commentator, which is acceptable in an objective news piece that presents different sides of an issue). So, the evaluators corrected the software by rejecting the suggestion as “not an opinion”—even though it was (it just didn’t belong to the author). As a result, we updated the software to recognize when an opinion was part of a quote or passage, so that it wouldn’t flag these to the evaluators.
The results
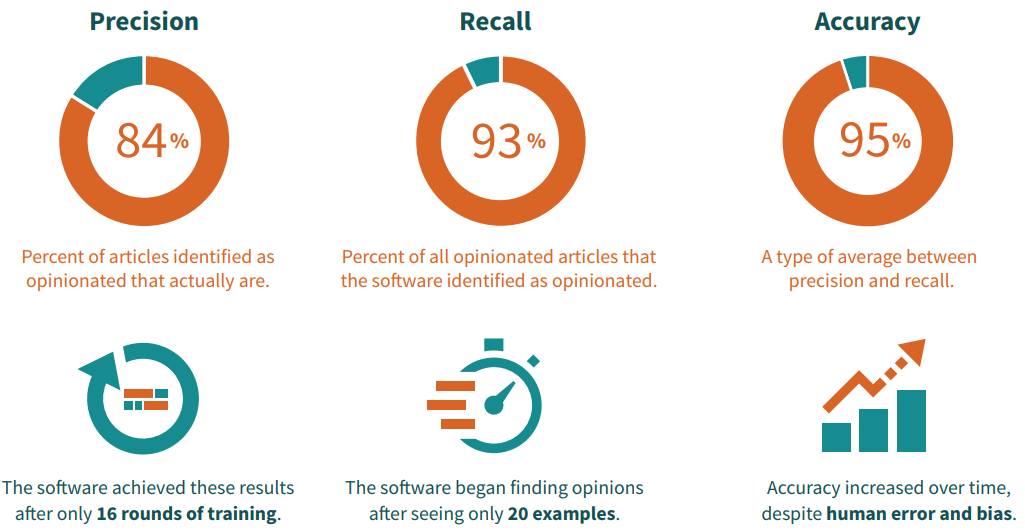
- The software recognized sentences containing opinions within the dataset of 1,200 articles with 95% accuracy. This means that, 95 out of 100 times it tries, the software can find an article containing an opinion.
- Accuracy and precision increased the more that the model was trained. There is a clear relationship between the number of times the evaluators trained the software and the accuracy and precision of the results. The recall results did not improve over time as consistently.
- The software’s ability to “learn” was almost immediately evident. Anecdotally, the evaluation team noticed a marked improvement in the accuracy of the software’s suggestions after showing it only twenty sentences that had opinions. The accuracy, precision, and recall results highlighted above were achieved after only sixteen rounds of training the software.
These results, although promising, simplify some numbers and calculations. Check out our full report for details.
What does this all mean? Let’s start with the good news. The results suggest that some parts of media quality—specifically, whether an article is impartial or whether it echoes its author’s opinions—can be automatically measured by machine learning. The software also introduces the possibility of unprecedented scale, scanning thousands of articles in seconds for this specific indicator. These implications introduce ways for media support programs to spend their limited resources more efficiently.
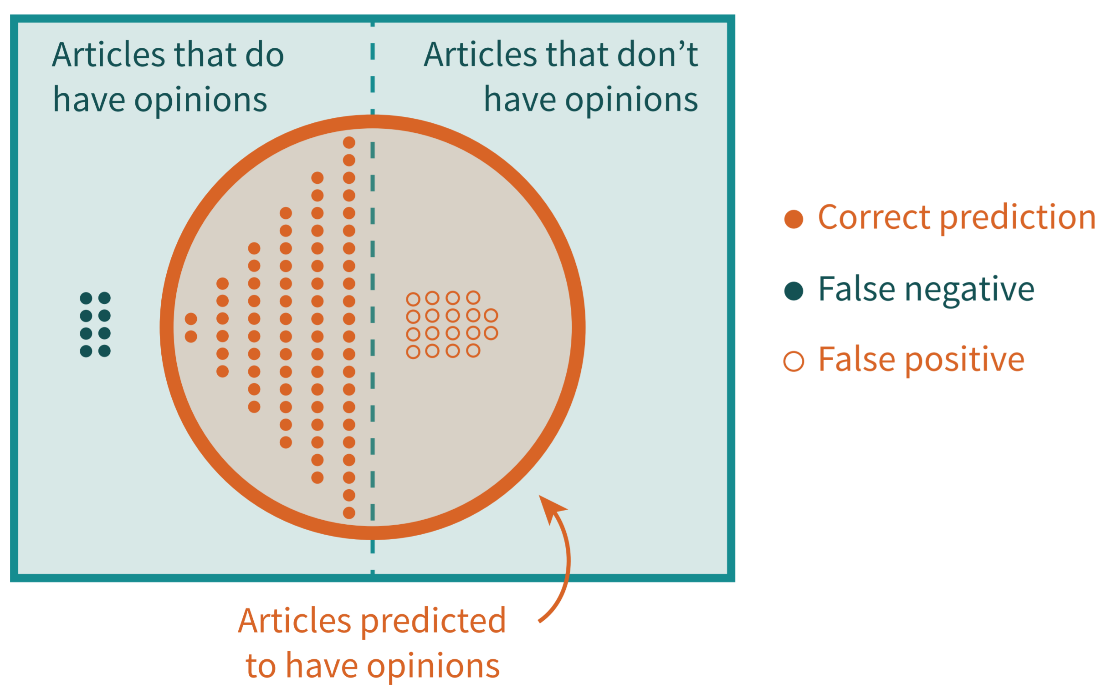
But this experiment also surfaced some important limitations about machine learning in our context as media practitioners. For instance, we must be aware about the evaluators’ own biases and how they’ve now been encoded into the software, and how sustainable our efforts are if the algorithms powering the software aren’t made openly available.
Also, there might be some indicators of media quality—such as whether news articles include diverse, reliable sources—that require too much contextual awareness and judgment for software to “learn”. This lesson is an important reminder that the goal of working with machine learning shouldn’t be to automate as many tasks as possible. Machine learning doesn’t replace our work, but it can help us work more intelligently and use our limited resources more efficiently
What’s next?
What does this mean for IREX and others in the media strengthening community?
Armed with this experience, we’re better prepared to start thinking critically about ways to adapt our programming according to what we learn with machine learning. For example, we can scan thousands of news articles produced by our trained reporters to learn which training efforts are having the strongest impact on the impartiality of their journalism. We could also compare their articles with others produced by journalists who were not supported by our programs, to better understand the impact of our initiatives. Or, we could run a periodic automatic scan of major news outlets in a country to get a pulse of the impartiality and quality of its information ecosystem at a macro level—a sort of “impartiality index”.
Of course, these ideas are illustrative and aspirational. More experimentation with machine learning is necessary to understand its potential and limitation. USAID recently called on development practitioners to “engage with machine learning technologies at an early stage,” and our experience through this pilot reinforces this need. Proactively exploring this rapidly advancing technology is the only way we can ensure that it’s applied responsibly and appropriately to support vibrant information across the globe.
Learn more about this experiment at www.irex.org/measuringnews.

Samhir Vasdev is the Advisor for Digital Development with the Center for Applied Learning and Impact at IREX, a global development and education organization. Find him on Twitter at @samhirvasdev.
Comments (0)